Monitoring PostgreSQL backups

In this guide, we'll create a simple shell script to perform database backups and upload them to S3, schedule these backups to run daily, and monitor their size, duration, and potential errors using AnomalyAlert.
- Prerequisites
- Backing up PostgreSQL and uploading backups
- Monitoring backup size, duration and errors
- Alerts for when backups don't run or fail
Prerequisites
This guide uses S3 as the offsite backup destination (though other object stores are equally easy to set up). Before we can start uploading our backups to S3, a bucket, policy and an access key need to be created and configured. With that in place, let's get started.
Install and configure AWS CLI
sudo apt update && sudo apt install awscli -yNote: This command is specific to systems that use the apt package manager, like Ubuntu and other Debian-based distributions. If you're using a different distribution, the command to install awscli may vary.
Next, we'll switch to the postgres user and configure our S3 credentials from there.
sudo -i -u postgres
aws configureYou'll be prompted for Access Key ID and Access Key Secret.
Backing up PostgreSQL and uploading backups
Backup to a local file
We'll backup the databases using pg_dump to create compressed backups, database-by-database. We'll write them to a temporary directory and have the filenames include the current date and time, as well as the database name.
backupdb.sh: #!/bin/bash
# List of database names to backup
DATABASES=("blog" "store")
for DB in "${DATABASES[@]}"; do
TIMESTAMP=$(date "+%Y%m%d%H%M")
BACKUP_FILE="/tmp/${TIMESTAMP}-${DB}.dump"
pg_dump -Fc $DB > $BACKUP_FILE
done This will loop through the list of database names we defined and back each one up to a file in /tmp.
Upload backups to S3
With the backup file in hand, we're now ready to upload it to our S3 bucket. Lets update our shell script:
#!/bin/bash
# List of database names to backup
DATABASES=("blog" "store")
# S3 bucket where backups will be uploaded
S3_BUCKET="s3://your-s3-bucket-name/path/"
for DB in "${DATABASES[@]}"; do
TIMESTAMP=$(date "+%Y%m%d%H%M")
BACKUP_FILE="/tmp/${TIMESTAMP}-${DB}.dump"
pg_dump -Fc $DB > $BACKUP_FILE
aws s3 cp $BACKUP_FILE $S3_BUCKET
# Remove the local backup file
rm -f $BACKUP_FILE
done Make the script executable using chmod +x backupdb.sh and run it by invoking ./backupdb.sh - you should see a console output similar to this:
upload: ../../../tmp/202310131952-blog.dump to s3://bucket-name/path
upload: ../../../tmp/202310131952-store.dump to s3://bucket-name/pathRunning backups daily
Great - we're backing up our databases and uploading those backups to an off-site object store. Now let's make sure we do this daily
We'll invoke crontab editor using crontab -e and add the following job:
0 0 * * * /var/lib/postgresql/backupdb.shThis will run our backup script every day at midnight.
Monitoring backup size, duration and errors
Our backups are now set to run periodically, but we won't find out if they fail for whatever reason - it could be that our S3 credentials aren't valid anymore, we've ran out of disk space while backing up or many other reasons.
We'll update our script to capture backup size, duration, as well as whether any errors were encountered during the backup file creation and upload steps, and pass this information on to AnomalyAlert.
Here's the final script:
#!/bin/bash
# Your AnomalyAlert API key
API_KEY="YOUR_API_KEY_HERE"
# Prefix to use in monitor names (your-prefix/database-name)
MONITOR_PREFIX="db-backups/"
# List of database names to back up
DATABASES=("blog" "store")
# S3 bucket where backups will be uploaded
S3_BUCKET="s3://your-s3-bucket-name/path/"
for DB in "${DATABASES[@]}"; do
TIMESTAMP=$(date "+%Y%m%d%H%M")
BACKUP_FILE="/tmp/${TIMESTAMP}-${DB}.dump"
BACKUP_SIZE=0
ERRORS=0
# Start timer and backup the database
start_time=$(date +%s)
pg_dump -Fc $DB > $BACKUP_FILE
if [ $? -eq 0 ]; then
# Measure backup size in megabytes
BACKUP_SIZE=$(du -sk $BACKUP_FILE | awk '{printf "%.2f", $1/1024}')
# Upload to S3
aws s3 cp $BACKUP_FILE $S3_BUCKET
if [ $? -ne 0 ]; then
# S3 upload failed - set errors to one
ERRORS=1
fi
else
# Backup failed - set errors to one
ERRORS=1
fi
# End timer
end_time=$(date +%s)
DURATION=$((end_time - start_time))
# Remove the local backup file
rm -f $BACKUP_FILE
# Post values to AnomalyAlert
curl -X POST "https://io.anomalyalert.com" \
-H "Content-Type: application/json" \
-d "{ \"api_key\": \"$API_KEY\", \"monitor\": \"$MONITOR_PREFIX$DB\", \"data\": { \"duration\": $DURATION, \"size\": $BACKUP_SIZE, \"errors\": $ERRORS }}"
doneThere's a couple of new variables we need to configure:
-
API_KEY- Your AnomalyAlert API key (it can be found under Settings) -
MONITOR_PREFIX- By default the database name will also be the monitor name. This prefix can be useful for organizing them (i.e.db-backups/will result in monitor namesdb-backups/blog, etc.)
Now, whenever our backup script is triggered, we'll keep track of the following information for each database:
-
duration- amount of time, in seconds, it took to create a backup and upload it to S3 size- backup size in megabytes-
errors- whether we encountered any errors during backup (0 or 1)
Let's run the backups now (./backupdb.sh) and refresh AnomalyAlert. You should now see a monitor created for each of the databases, as well as the 3 metrics we're collecting for each of them:
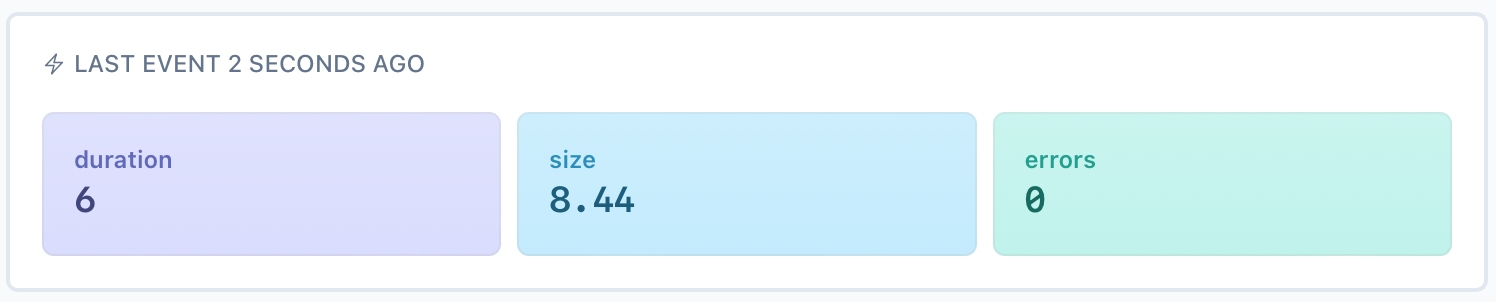
Alerts for when backups don't run or fail
With monitors and data collection in place, it's time for us to set up our alerts. Click on Configure alerts on your monitor.
We'll add 3 rules that will trigger alerts whenever either of them is violated:
- No backups have been created in more than 1 day
- There were errors during backup process
- Backup size is less than 10MB (adjust accordingly for your database size)
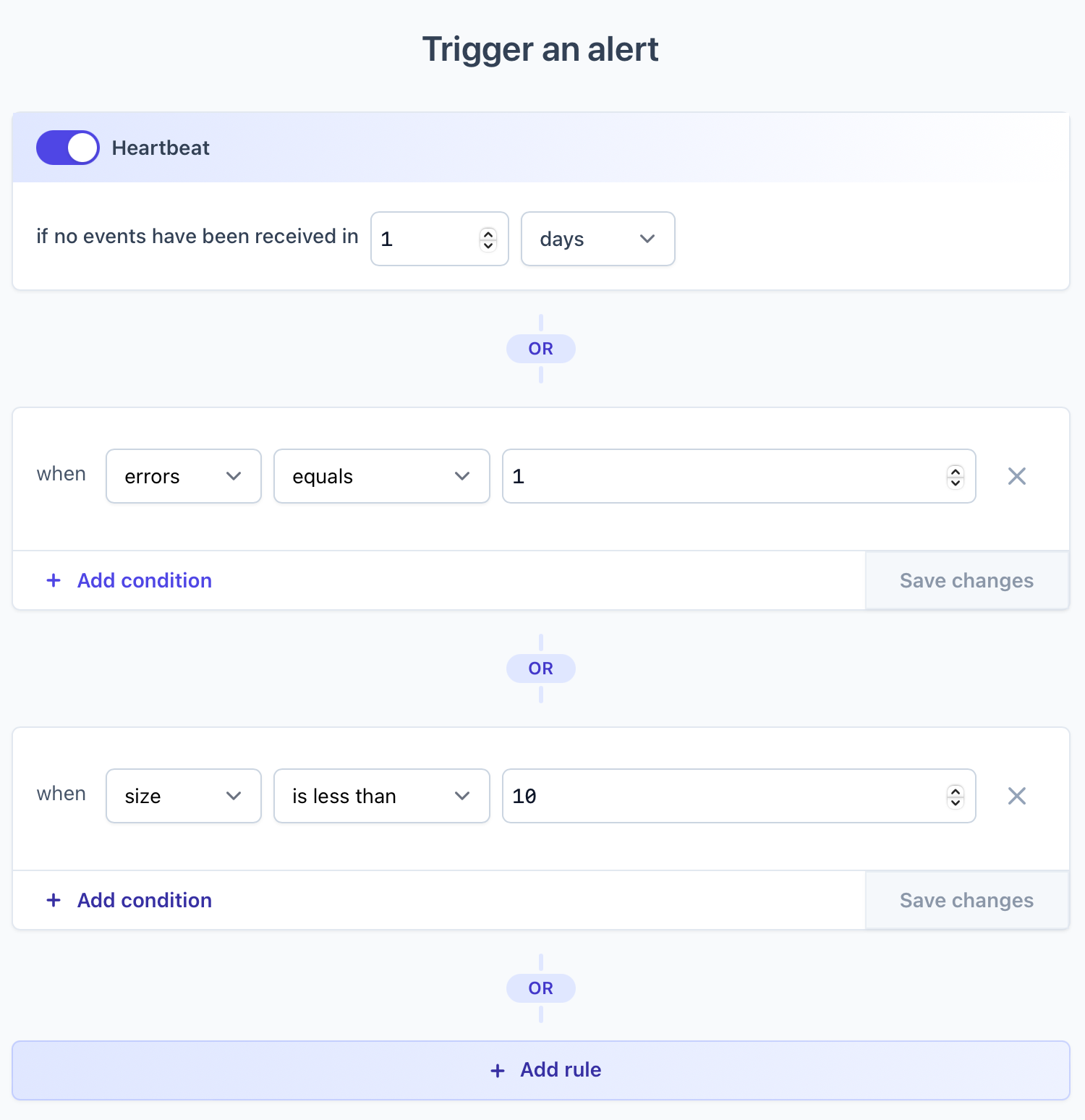
That's it. We can now sleep better knowing that as soon as something goes wrong with our database backups, we'll get notified!